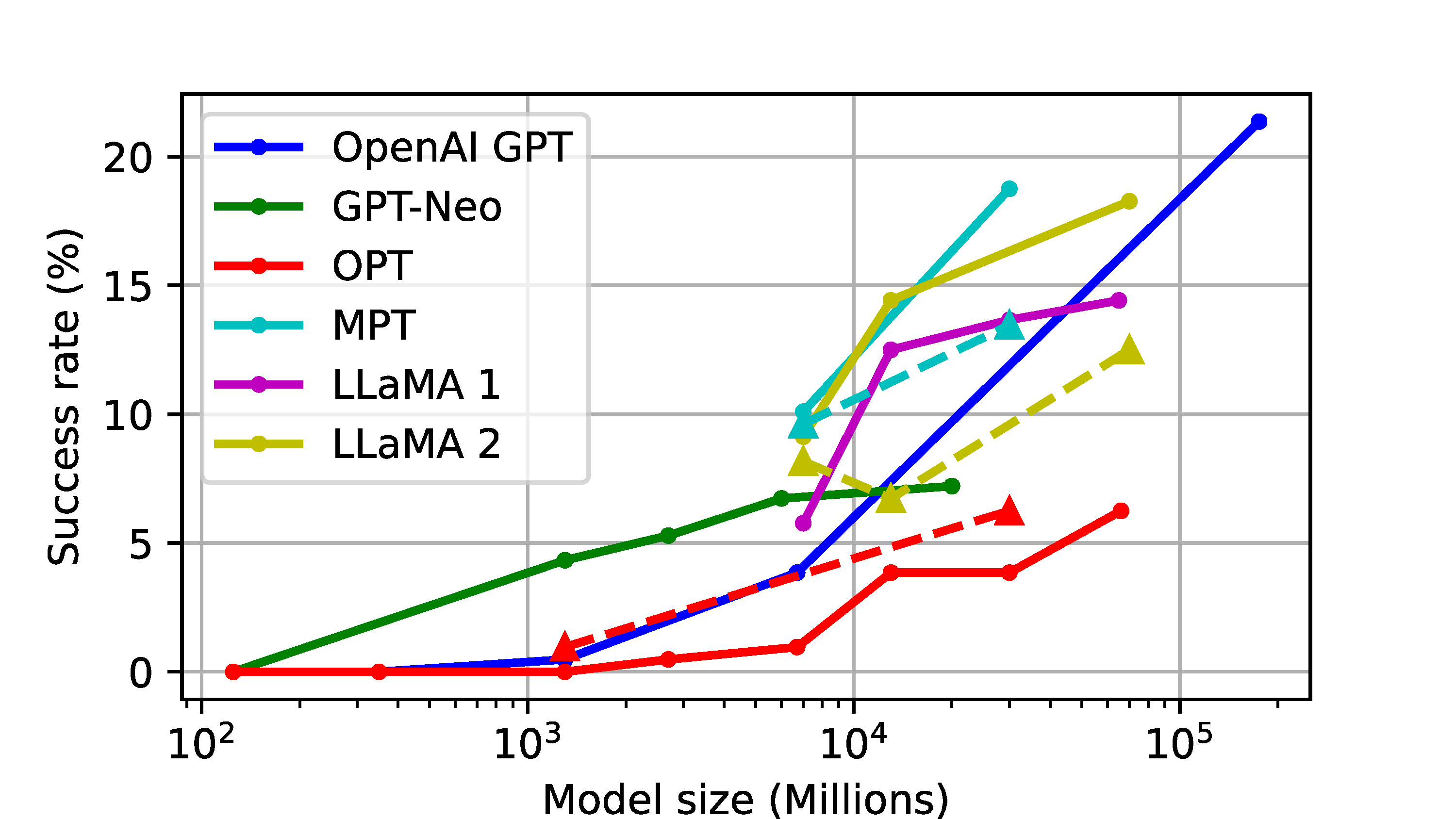
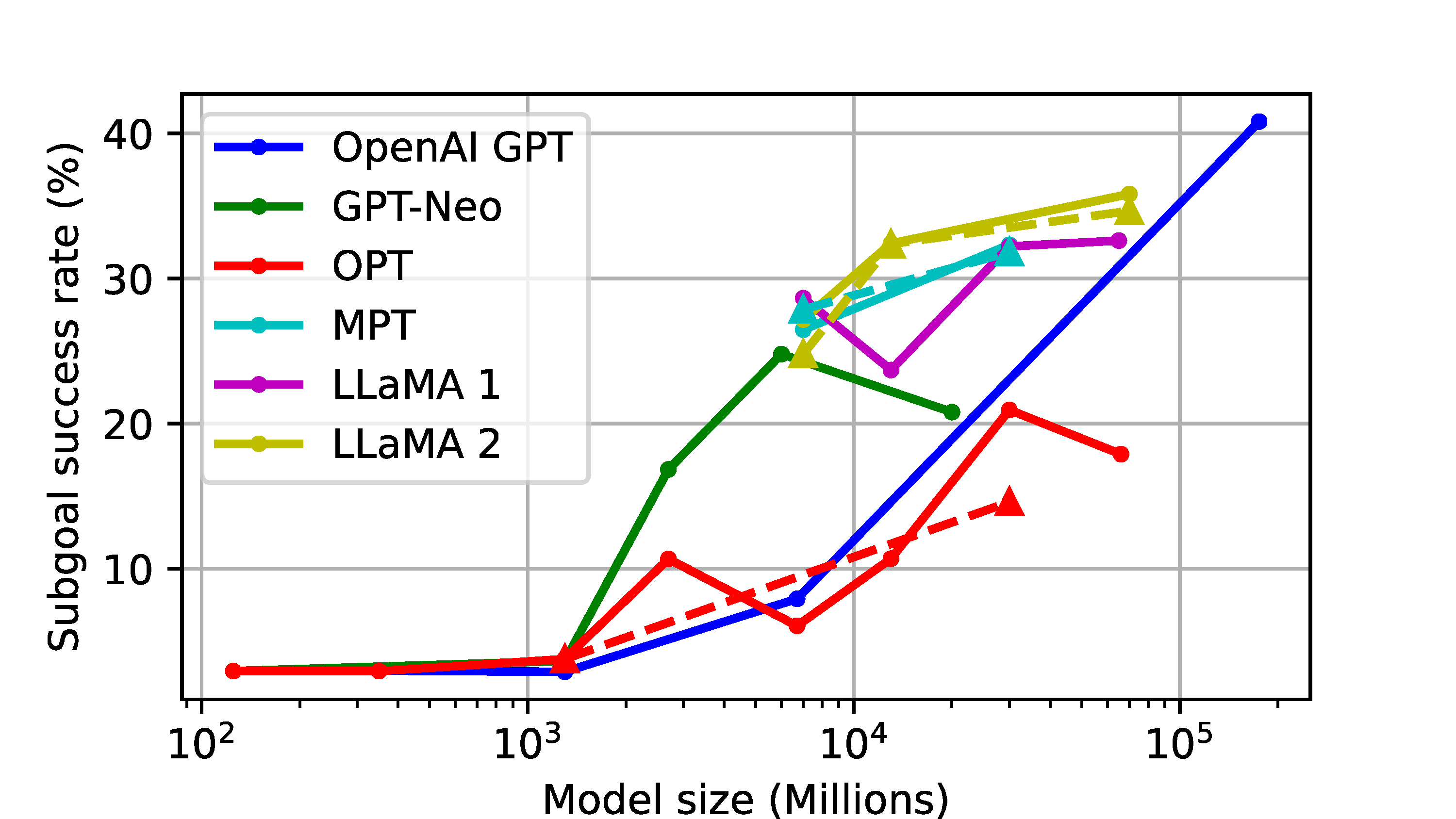
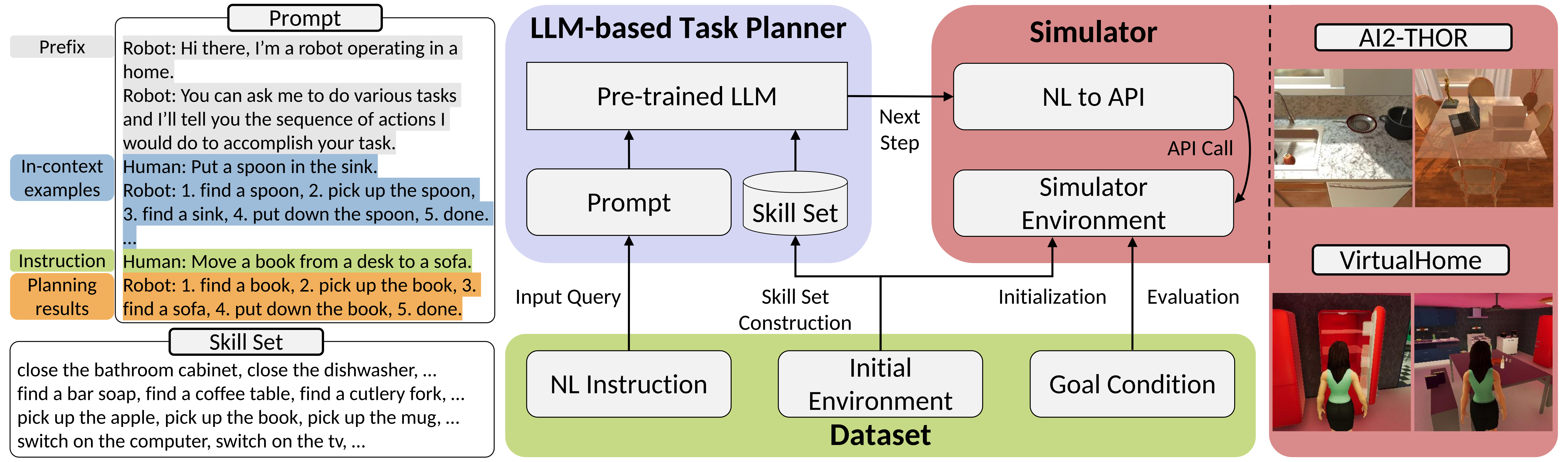
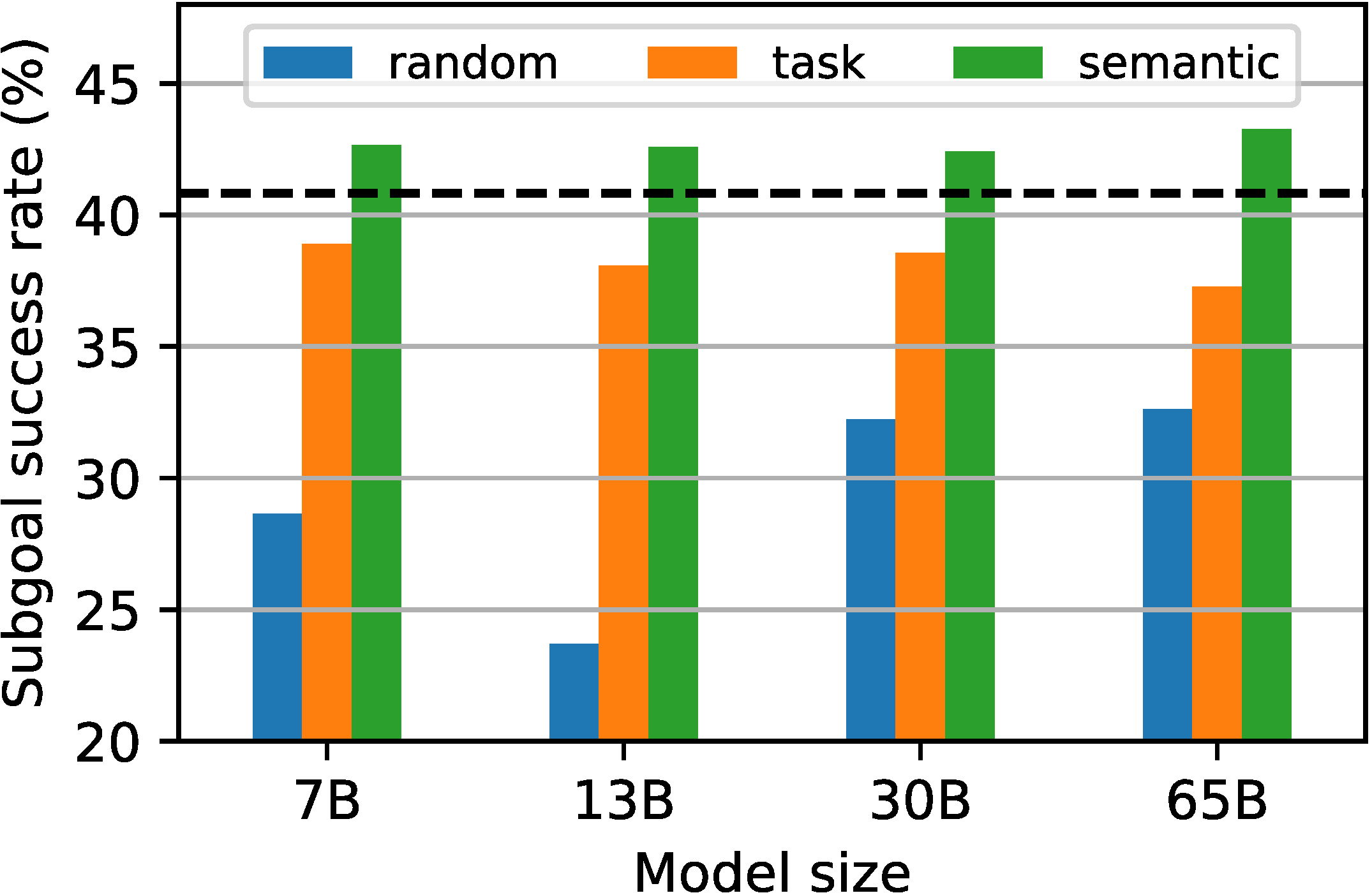
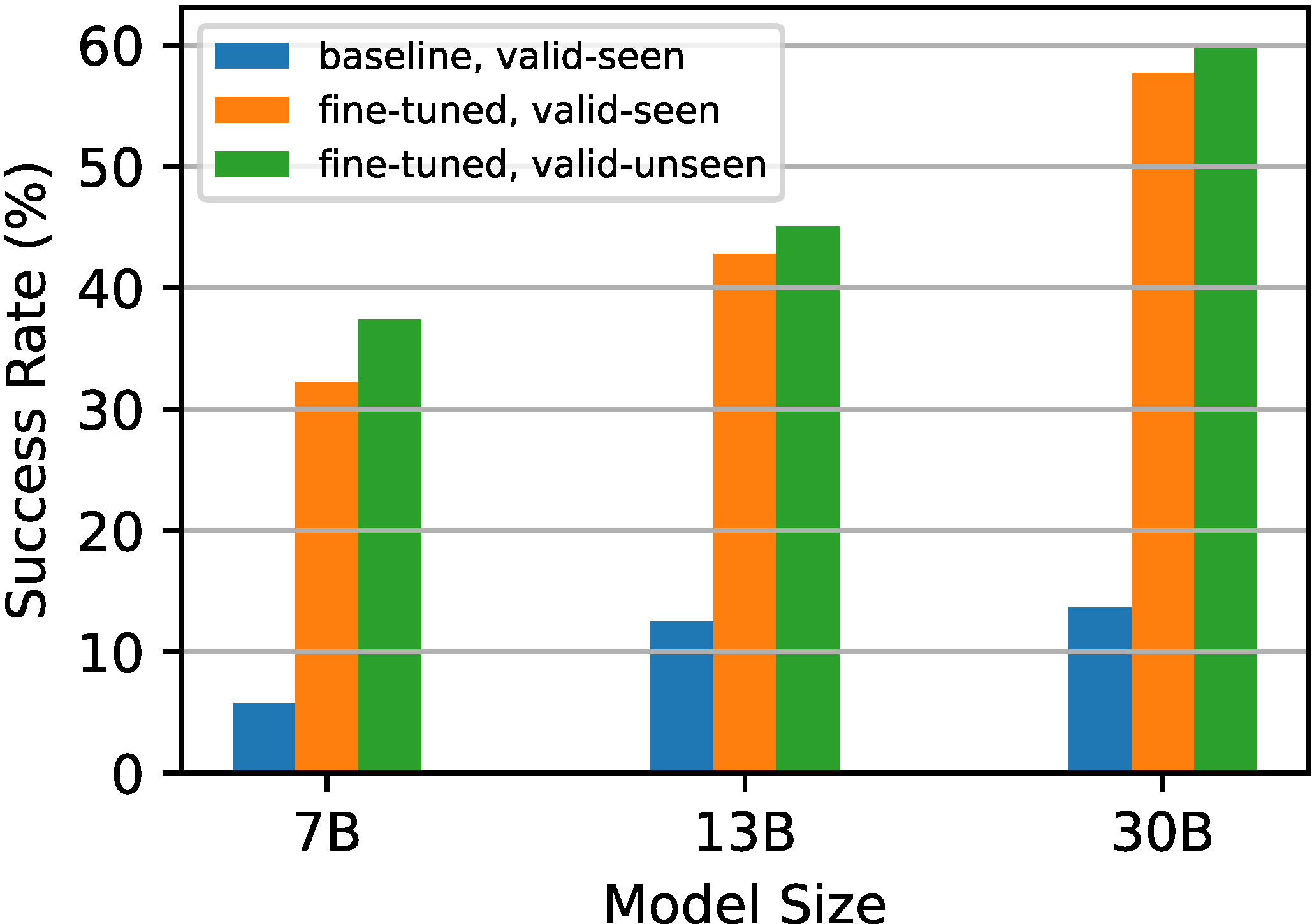
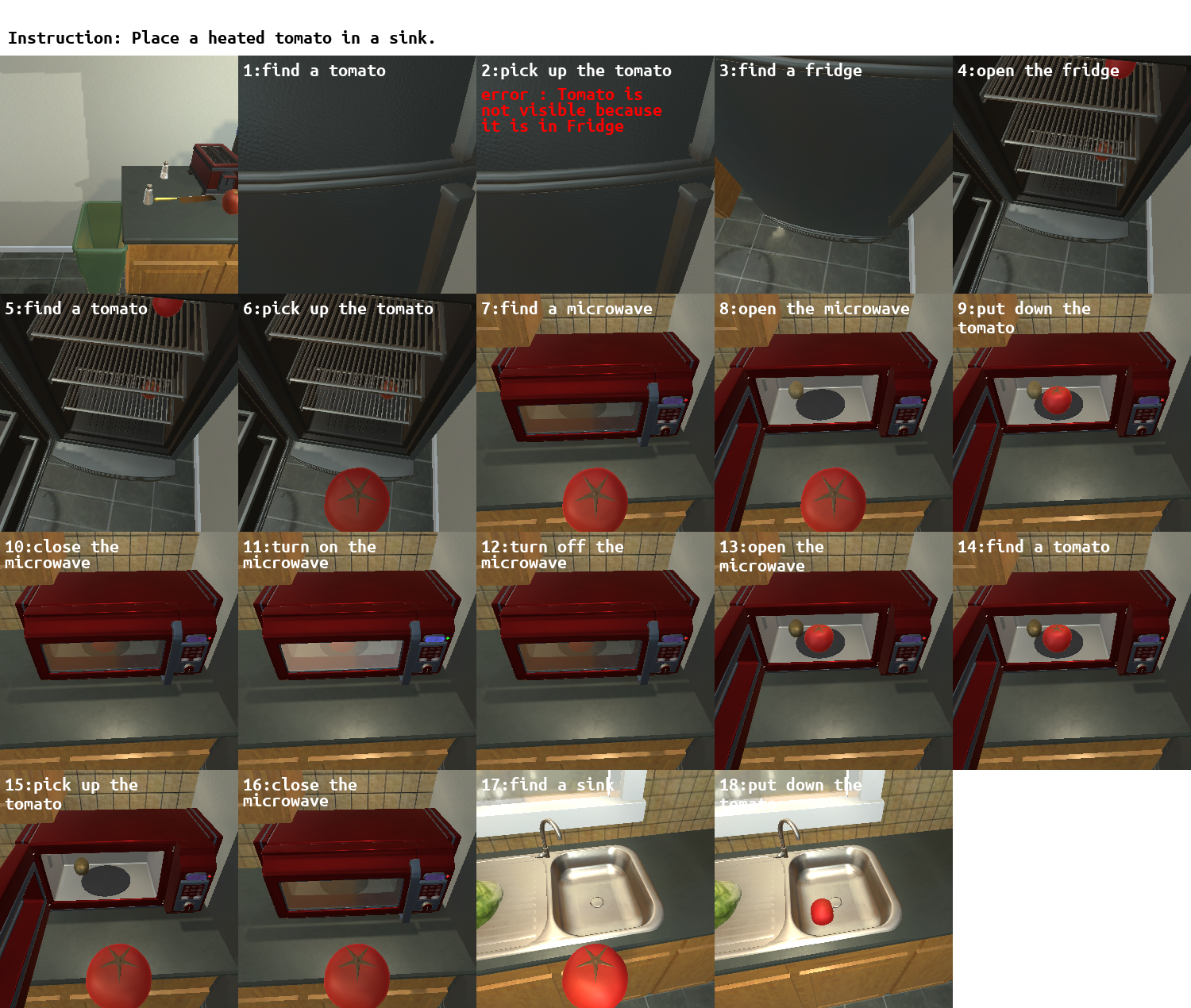
To rigorously evaluate LLM-based task planners, we introduce a comprehensive evaluation framework, LoTa-Bench. The framework integrates three key components: a task planner, a dataset, and a simulator. Our baseline task planner leverages the in-context learning capabilities of LLMs. Then we offer two distinct dataset-simulator pairings: 1) the ALFRED dataset built on the AI2-THOR simulator, and 2) an extended version of the Watch-And-Help (WAH) dataset, named WAH-NL, incorporated with the VirtualHome simulator. The following images depict samples where the LLM-based task planner, utilizing the GPT-3 175B model, has successfully planned and executed desired tasks within the simulator.